tl;dr
- The type of UUIDs used as primary keys affects INSERT performance in DB2 LUW
- Use UUIDv7 (with time-based ordering) if you choose to use UUIDs as primary keys
- Update June 2026: re-tested with PostgreSQL 18 and Db2 12.1 – UUIDv7 stays clearly ahead, and on Db2 the gap is now even larger
Update (June 2026)
I re-ran the test with current versions: PostgreSQL 18 and Db2 LUW 12.1. For Db2 I now use BINARY(16) as the key type instead of CHAR(16) FOR BIT DATA.
UUIDv7 versus UUIDv4, INSERT of 100,000 rows (average):
| Database | 3 million rows | 10 million rows |
|---|---|---|
| PostgreSQL 18 | ~20% faster | ~39% faster |
| Db2 LUW 12.1 | ~20% faster | ~25% faster |
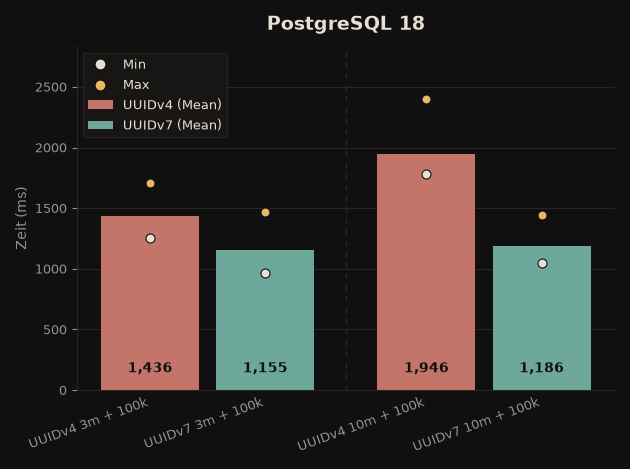
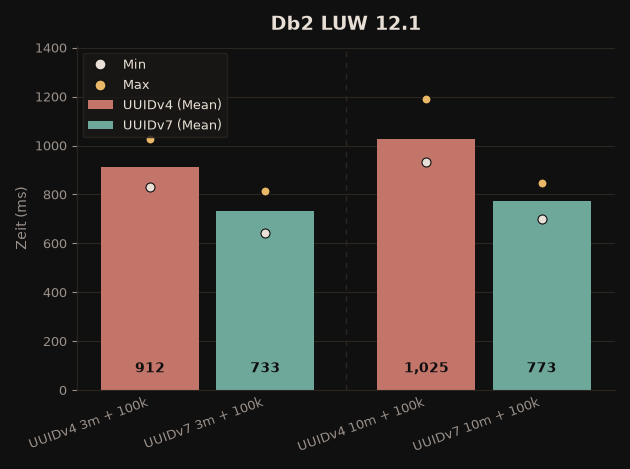
On Db2, the UUIDv7 advantage is now considerably larger than in the original test (back then ~3–10%). The recommendation stands: always prefer UUIDv7 as a primary key!
Setup: Hetzner CPX32 (AMD, 4 vCPU, 8 GB RAM), both databases as Docker containers, Java 25 (Temurin), Spring Boot 4.1.
The original article from 2024 follows unchanged.
Motivation
During one of my DB2 training sessions, someone asked if the type of UUIDs affects database performance. Specifically, whether random or sortable UUIDs are better to use.
For PostgreSQL, I knew the answer: Primary keys need to be ordered so the B-tree index requires less frequent rebalancing.
However, I wasn't sure how it works with DB2. My assumption was that a similar effect might occur there.
About UUIDs
Since May 2024, there's a new RFC standard that addresses different types of UUIDs.
For primary keys, two main variants are relevant:
- UUIDv4: randomly generated, no sorting possible
- UUIDv7: starts with a Unix Epoch timestamp, followed by random data, making it sortable by creation time
So the question is: "If I use UUIDs as primary keys in DB2, should I choose UUIDv4 or UUIDv7?"
Test Setup
This question piqued my curiosity, so I decided to investigate further.
To get to the bottom of it, I created a test setup using a Spring Boot application. First, I populate a table with some data, and then I measure how long a batch INSERT of 100,000 rows takes. I run the test once with UUIDv4 as primary keys and once with UUIDv7.
In Java, UUIDv4 can be generated directly using UUID.randomUUID(). For UUIDv7, you currently need to use a library or write some custom code.
The code to insert the data looks something like this:
public void insertBatchJdbcClient(List<User> users, int batchSize) {
jdbcTemplate
.batchUpdate("""
INSERT INTO test_user (id, username, password)
VALUES (?, ?, ?);
""",
users, batchSize,
(ps, argument) -> {
ps.setObject(1, argument.id());
ps.setString(2, argument.username());
ps.setString(3, argument.password());
});
}
Part I: PostgreSQL
With PostgreSQL, I was able to reproduce well-known results: UUIDv4 (random): The random distribution of keys made the B-tree index work harder. UUIDv7 (time-ordered): Significantly reduced index rebalancing and delivered much better performance.
- With 3 million rows: ~30% faster.
- With 10 million rows: ~40% faster.
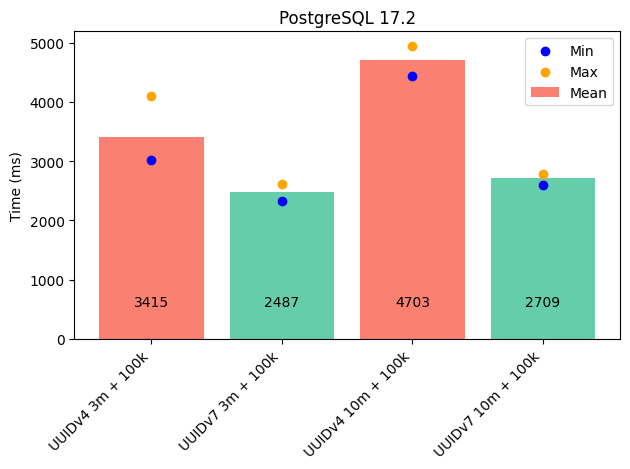
The data type I used for the primary key was UUID.
Part II: DB2
With DB2, the expected effect was observed as well — though it was less pronounced compared to PostgreSQL.
- With 3 million rows: ~3% faster.
- With 10 million rows: ~10% faster.
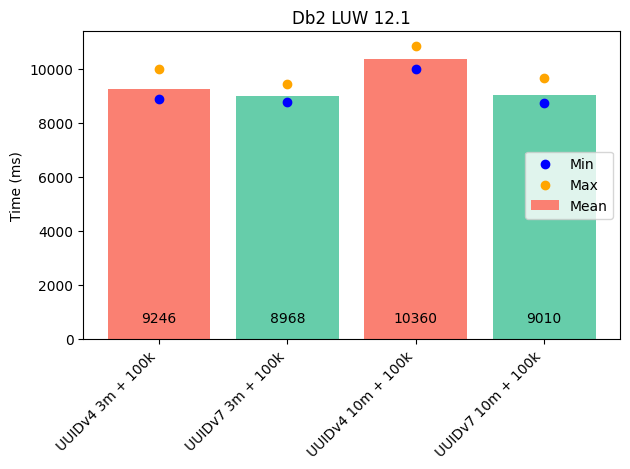
The data type I used for the primary key was CHAR(16) FOR BIT DATA.
Conclusion
UUIDv7 provides performance advantages not only with PostgreSQL but also with DB2, although the benefits are smaller in the latter case.
New code should prefer UUIDv7 as a primary key if you decide to use UUIDs in general. For insert-heavy workloads, this can result in a noticeable performance improvement.
Whether you should migrate existing tables and code from another type of UUID to UUIDv7 depends on the effort involved and the workload on the data.
For comments or feedback, feel free to reach out at info (at) leonardw (dot) de.
FAQ
UUIDv4 or UUIDv7 as a primary key?
UUIDv7. Thanks to its time-based ordering, the index needs rebalancing less often, so INSERTs are faster.
Which data type for UUIDs in DB2 LUW?
BINARY(16) – 16 bytes, no code page overhead. The older, equivalent option is CHAR(16) FOR BIT DATA.
Which data type for UUIDs in PostgreSQL?
The native UUID type. Don't store them as text (varchar).
Why is UUIDv7 faster on INSERT than UUIDv4?
New keys land at the end of the index. That reduces page splits and B-tree rebalancing compared to random UUIDv4.
Should I migrate existing tables to UUIDv7?
It depends. For insert-heavy, large tables it can pay off – weigh the migration effort against the gain.
Does UUIDv7 have downsides?
The timestamp is readable, so the creation time of a row isn't secret. For internal primary keys this is usually fine.
Does this also apply to MySQL, Oracle or SQL Server?
The principle is the same everywhere: ordered keys ease the load on the index. I only measured PostgreSQL and DB2 here.
Technical Details
The following setup was used for the tests.
Server
- Hetzner cpx21
- 4 cores Intel, x86, shared
- 8 GB RAM
- Ubuntu 24.04
DB2
- DB2 LUW 12.1 running as a Docker container
- Default settings
- Exception: Log size increased to 5k
- Batch size 5000
PostgreSQL
- PostgreSQL 17.2 running as a Docker container
- Default settings
- Batch size 250
Java 21 (Temurin), Spring Boot 3.4