tl;dr
- Die Art der UUIDs als Primärschlüssel hat Auswirkungen auf die INSERT Performance bei DB2 LUW
- Nutze UUIDv7 (mit zeitlicher Ordnung) wenn du UUIDs als Primärschlüssel einsetzt
- Update Juni 2026: erneut mit PostgreSQL 18 und Db2 12.1 getestet – UUIDv7 bleibt klar vorn, bei Db2 jetzt sogar deutlicher
Update (Juni 2026)
Ich habe den Test mit aktuellen Versionen wiederholt: PostgreSQL 18 und Db2 LUW 12.1. Als Schlüsseltyp nutze ich bei Db2 jetzt BINARY(16) statt CHAR(16) FOR BIT DATA.
UUIDv7 gegenüber UUIDv4, INSERT von 100.000 Zeilen (Durchschnitt):
| Datenbank | 3 Mio. Rows | 10 Mio. Rows |
|---|---|---|
| PostgreSQL 18 | ~20 % schneller | ~39 % schneller |
| Db2 LUW 12.1 | ~20 % schneller | ~25 % schneller |
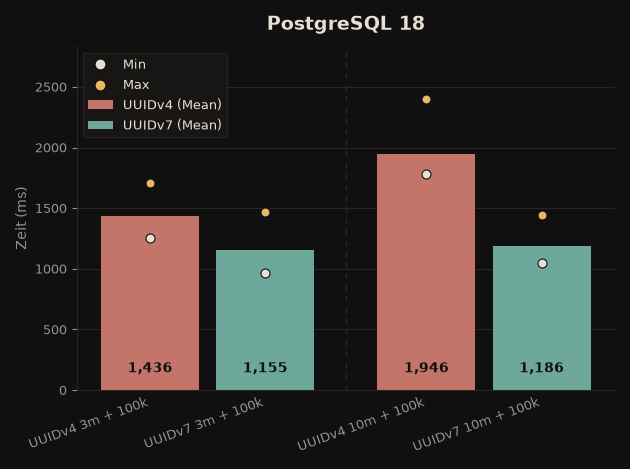
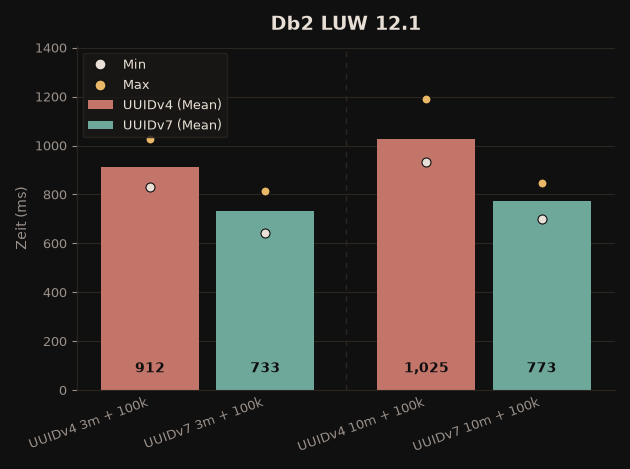
Bei Db2 fällt der Vorteil von UUIDv7 damit deutlich größer aus als im ursprünglichen Test (damals ~3–10 %). Die Empfehlung bleibt: UUIDv7 als Primärschlüssel immer bevorzugen!
Setup: Hetzner CPX32 (AMD, 4 vCPU, 8 GB RAM), beide Datenbanken als Docker-Container, Java 25 (Temurin), Spring Boot 4.1.
Der ursprüngliche Artikel von 2024 folgt unverändert.
Motivation
In einer meiner Schulungen zu DB2 kam die Frage auf, ob sich die Art von UUIDs auf die Performance der Datenbank auswirkt. Also ob man besser zufällige oder sortierbare UUIDs nutzen sollte.
Für PostgreSQL kannte ich die Antwort: Dort müssen Primärschlüssel eine Ordnung aufweisen, damit der B-Tree des Indexes seltener neu balanciert werden muss.
Wie sich das jedoch bei DB2 verhält, wusste ich nicht. Meine Vermutung war aber, dass dort ein ähnlicher Effekt zu beobachten sein sollte.
Über UUIDs
Seit Mai 2024 gibt es einen neuen RFC Standard, der sich mit verschiedenen Arten von UUIDs beschäftigt.
Für Primärschlüssel kommen im Wesentlichen zwei Varianten infrage:
- UUIDv4: zufällig generiert, keine Sortierung möglich
- UUIDv7: beginnt mit Unix Epoch Timestamp, anschließend zufällig, ist somit nach Einstellzeitpunkt sortierbar
Die Frage lautet also: "Wenn ich UUIDs als Primärschlüssel in DB2 verwende, sollte ich UUIDv4 oder UUIDv7 nehmen?"
Testaufbau
Diese Frage hat mich neugierig gemacht, und ich habe beschlossen, das Ganze genauer zu untersuchen.
Um der Sache auf den Grund zu gehen, habe ich ein Testsetup als Spring Boot Anwendung erstellt. Damit fülle ich zunächst eine Tabelle mit einigen Daten und anschließend messe ich, wie lange ein Batch INSERT von 100.000 Zeilen benötigt. Das Ganze einmal mit UUIDv4 als Primärschlüssen und einmal mit UUIDv7.
In Java können UUIDv4 direkt über UUID.randomUUID() erzeugt werden. Für eine UUIDv7 muss man aktuell noch eine Library einbinden oder selbst etwas Code schreiben.
Der Code zum Einfügen der Daten sieht in etwa so aus:
public void insertBatchJdbcClient(List<User> users, int batchSize) {
jdbcTemplate
.batchUpdate("""
INSERT INTO test_user (id, username, password)
VALUES (?, ?, ?);
""",
users, batchSize,
(ps, argument) -> {
ps.setObject(1, argument.id());
ps.setString(2, argument.username());
ps.setString(3, argument.password());
});
}
Teil I: PostgreSQL
Bei PostgreSQL konnte ich bekannte Ergebnisse reproduzieren: UUIDv4 (random): Zufällig Verteilung der Schlüssel erschwerte dem B-Tree-Index die Arbeit. UUIDv7 (zeitlich geordnet): Reduziert die Neubalancierung des Indexes merklich und lieferte deutlich bessere Performance.
- Bei 3 Millionen Rows: ~30 % schneller.
- Bei 10 Millionen Rows: ~40 % schneller.
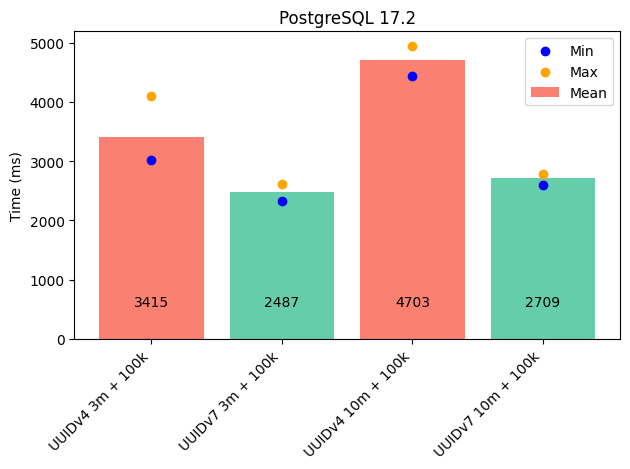
Als Datentyp für den Primärschlüssel habe ich UUID verwendet.
Teil II: DB2
Auch bei DB2 zeigte sich der erwartete Effekt - wenngleich auch weniger stark als bei PostgreSQL.
- Bei 3 Millionen Rows: ~3 % schneller.
- Bei 10 Millionen Rows: ~10 % schneller.
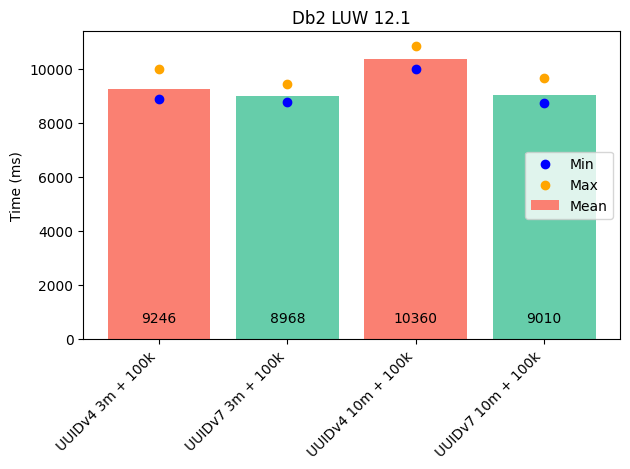
Als Datentyp für den Primärschlüssel habe ich CHAR(16) FOR BIT DATA verwendet.
Fazit
UUIDv7 bietet nicht nur bei PostgreSQL, sondern auch bei DB2 Performancevorteile – wenngleich auch diese geringer ausfallen.
In neuen Code sollte somit auf UUIDv7 als Primärschlüssel gesetzt werden, falls man sich generell entscheidet UUIDs zu verwenden. Für Insert-lastige Workloads kann sich dadurch ein erkennbarer Performancevorteil ergeben.
Ob man bestehende Tabellen und Code von einer anderen Art UUID auf UUIDv7 umstellen sollte, hängt vom Aufwand und vom Workload auf den Daten ab.
Für Anmerkungen oder Feedback schreibt mir gerne unter info (at) leonardw (punkt) de
FAQ
UUIDv4 oder UUIDv7 als Primärschlüssel?
UUIDv7. Durch die zeitliche Ordnung muss der Index seltener neu balanciert werden, INSERTs sind schneller.
Welcher Datentyp für UUIDs in Db2 LUW?
BINARY(16) – 16 Byte, ohne Codepage-Overhead. Älterer, gleichwertiger Weg: CHAR(16) FOR BIT DATA.
Welcher Datentyp für UUIDs in PostgreSQL?
Der native UUID-Typ. Nicht als Text (varchar) speichern.
Warum ist UUIDv7 beim INSERT schneller als UUIDv4?
Neue Schlüssel landen am Ende des Index. Das reduziert Page-Splits und Neubalancierung des B-Trees gegenüber zufälligen UUIDv4.
Sollte ich bestehende Tabellen auf UUIDv7 migrieren?
Kommt drauf an. Bei insert-lastigen, großen Tabellen kann es sich lohnen – Migrationsaufwand gegen den Gewinn abwägen.
Hat UUIDv7 Nachteile?
Der Zeitstempel ist auslesbar, der Erstellzeitpunkt eines Datensatzes also nicht geheim. Für interne Primärschlüssel meist unkritisch.
Gilt das auch für MySQL, Oracle oder SQL Server?
Das Prinzip ist überall gleich: geordnete Schlüssel entlasten den Index. Gemessen habe ich hier nur PostgreSQL und Db2.
Kleingedrucktes
Folgendes Setup habe ich für die Tests verwendet.
Server
- Hetzner cpx21
- 4 Cores intel, x86, shared
- 8 GB RAM
- Ubuntu 24.04
DB2
- DB2 LUW 12.1 als Docker Container
- Default Einstellungen
- Ausnahme Logsize: erhöht auf 5k
- Batch Size 5000
PostgreSQL
- PostgreSQL 17.2 als Docker Container
- Default Einstellungen
- Batch Size 250
Java 21 (Temurin), Spring Boot 3.4